Da Coqui AI bereits Anfang 2024 geschlossen hat, wird ihre Open Source TTS Lösung Coqui TTS im entsprechenden Github Projekt nicht weiter gepflegt 😥. Dies zeigt sich jetzt bei der Abhängigkeit zur Python Version. So funktioniert das offizielle Coqui TTS Paket nur bis Python Version 3.11. Schon ab 3.12 lässt sich das Paket nicht mehr installieren.
Glücklicherweise gibt es einen Fork bei Github, welches die Lauffähigkeit auch bei neuerem Python Versionen ermöglicht 🥳.
Ich habe die Dokumentation entsprechend angepasst und hoffe, dass meine Thorsten-Voice Coqui Modelle so noch einige Zeit funktionieren werden.
Mittelfristig kann ich aber einen Wechsel zu meinen Piper TTS Modellen empfehlen. Die gibt es nicht nur in …
Hochdeutsch
sondern auch in emotionaler Betonung
und in charmantem südhessischen Dialekt
Ich wünsche euch ganz viel Spaß mit meinen „Thorsten-Voice’s“ 😊
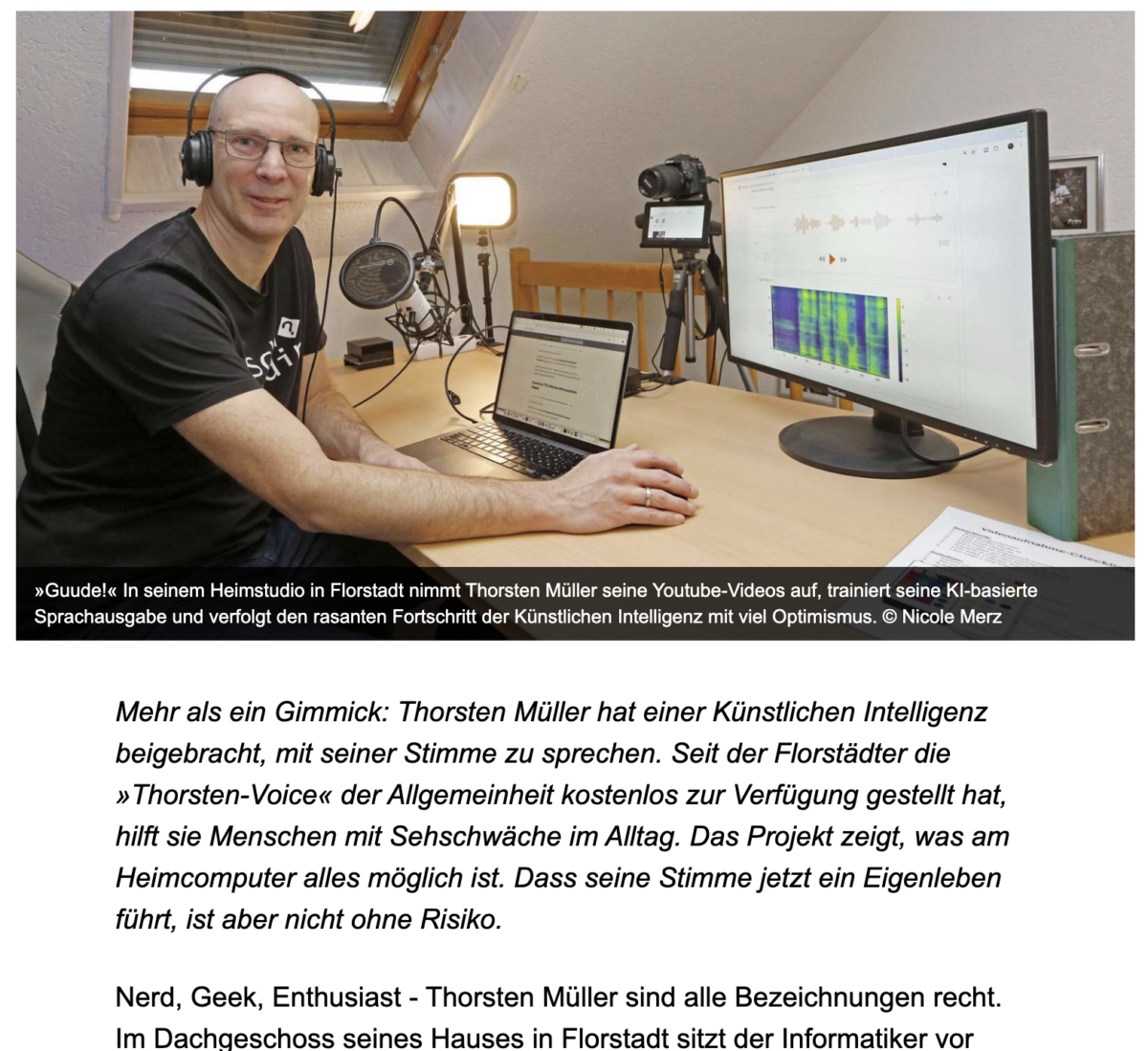
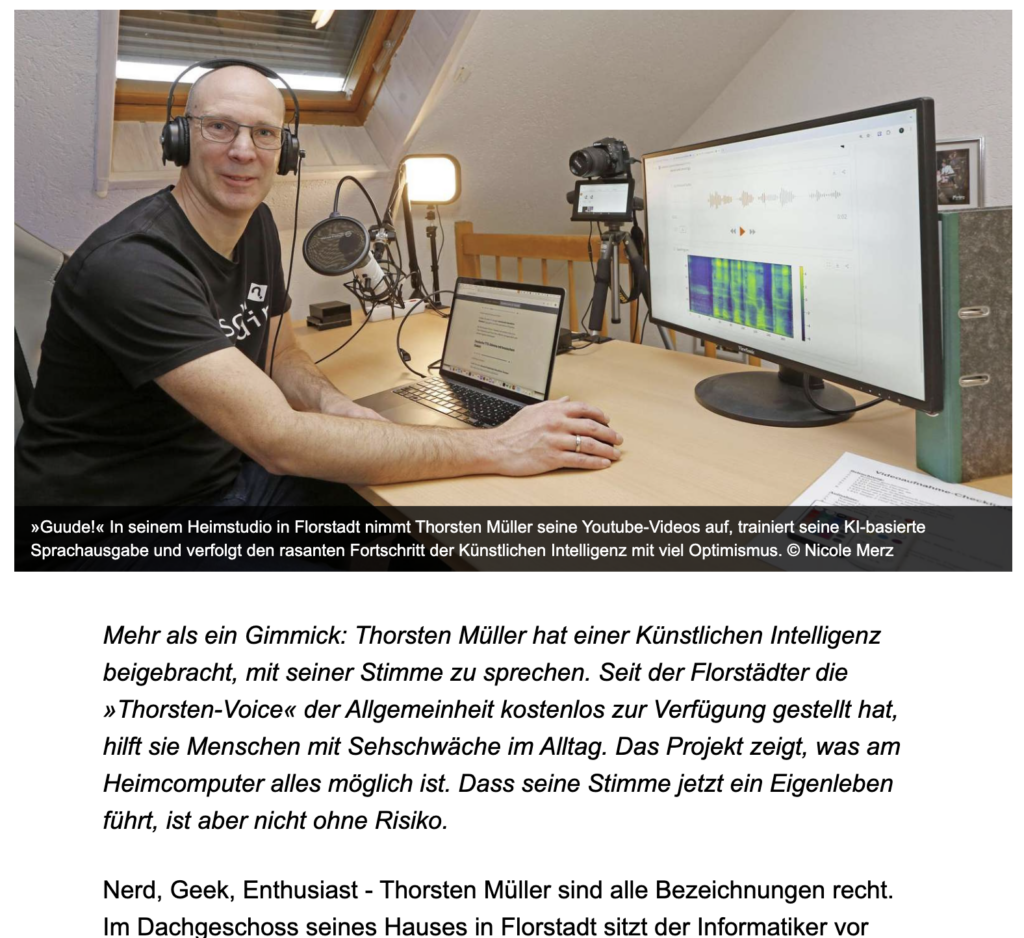
Ich fühle mich geehrt, dass die Wetterauer-Zeitung, die Frankfurter Neue Presse sowie die Frankfurter Rundschau einen Artikel über mein Thorsten-Voice Projekt veröffentlicht haben.
Transform your Text-to-Speech output from robotic to natural-sounding with proper text preprocessing (cleaning / normalization). My Youtube step-by-step tutorial shows you how to handle numbers, abbreviations, and special characters to significantly improve your TTS quality. This works for ANY TTS, not just fancy AI based text-to-speech models, but espeak / mbrola, too.
Video Tutorial
Why Text Cleaning Matters
When feeding text into a TTS system, certain elements can cause unnatural speech patterns:
Abbreviations like „Dr.“ or „Mr.“ are interpreted as sentence endings
Numbers are read digit by digit instead of naturally
Special characters and symbols may cause unexpected pauses
Time formats and dates might be misinterpreted
„Bad“ text input to TTS: „Dr. Smith paid $1,234 for 2 items at 3pm after waiting outside at 72°F on may, 15th, 2024. While waiting for the train to arrive at 15:45 he called a support hotline at 1-800-555-0123.„
Text NOT cleaned / normalized and spoken with Piper TTS.
This is hard for most TTS systems, because it contains lots of special characters that are hard to pronounce correctly for TTS.
„Better“ text input keeping the same sentence: „Doctor Smith paid one thousand two hundred thirty-four dollars for two items at three p m after waiting outside at seventy-two degrees Fahrenheit on May fifteenth, twenty twenty-four. While waiting for the train to arrive at fifteen forty-five he called a support hotline at one eight hundred five five five zero one two three.„
Text CLEANED / NORMALIZED and spoken with Piper TTS.
The Solution: Text Preprocessing
Below you’ll find a Python script that handles common text cleaning tasks. It works with any TTS system, including Piper, Coqui, eSpeak, and others.
Features:
Converts numbers to words (e.g., „123“ → „one hundred twenty-three“)
YouTube Success: Thorsten-Voice Celebrates a Remarkable Year 2024 in AI and Language Technology
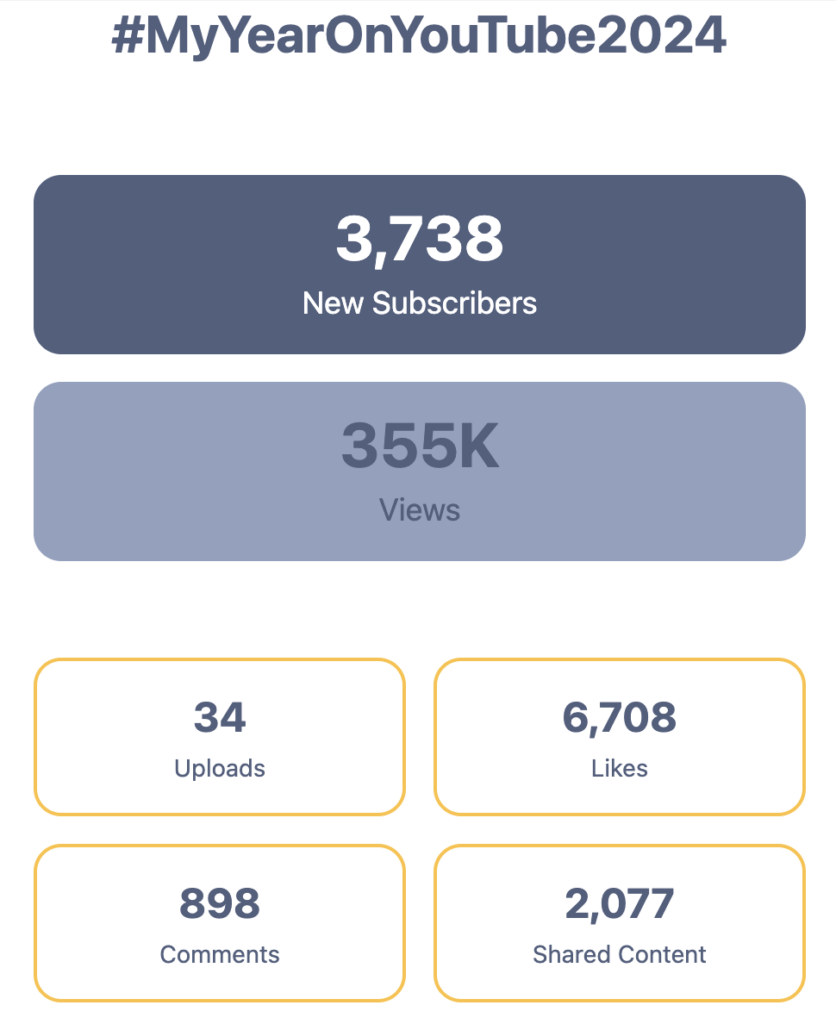
2024 has been an exceptional year for my Thorsten-Voice YouTube channel, marking significant growth in our AI and language technology community. With over 355,000 views and 3,738 new subscribers, i’ve seen unprecedented engagement in open-source AI discussions and tutorials.
2024 YouTube Statistics Highlight Community Growth
My channel’s performance reflects the growing interest in AI and language technology:
355K total video views
3,738 new subscribers
34 in-depth uploads
6,708 likes showing content appreciation
898 engaging comments
2,077 shares expanding our reach
Building a Strong AI Technology Community
The numbers tell a story of community engagement and knowledge sharing. Each of the 34 uploads sparked discussions about open-source AI, language models, and their practical applications. The nearly 900 comments represent valuable exchanges and learning opportunities within our community.
Looking Forward to 2025
As we approach 2025, Thorsten-Voice remains committed to providing high-quality content about AI voice technology, open-source developments, and language processing innovations. Our growing community of developers, researchers, and AI enthusiasts continues to drive meaningful discussions and knowledge sharing.
Join my AI Voice Technology Journey
Whether you’re a developer, researcher, or AI enthusiast, we invite you to join our community. Subscribe to Thorsten-Voice on YouTube to stay updated with the latest in AI and language technology developments.
NEW VIDEO SERIES: The smart home community has long awaited a reliable, privacy-focused voice assistant solution. With the release of Home Assistant Voice Preview Edition, this wait might finally be over. I’m excited to present my comprehensive tutorial series that guides you through everything you need to know about this promising new device.
What’s This Series About?
This series walks you through the Home Assistant Voice Preview Edition from unboxing to advanced setup. Whether you’re new to Home Assistant or an experienced user, these tutorials will help you understand and implement voice control in your smart home setup.
Available Episodes
Episode 1: Unboxing & Tech Specs
In this first episode, we dive into the unboxing experience and examine the technical specifications of the Home Assistant Voice Preview Edition. Get your first look at the hardware and learn what makes it tick. Watch Episode 1
Episode 2: First Setup & Connection
The second episode guides you through the initial setup process. Learn how to power on the device and connect it to your Home Assistant installation. We’ll also explore the entities created during setup. Watch Episode 2
Episode 3: Local Setup with Whisper & Piper
In this episode, we tackle local voice processing setup using Whisper for speech recognition and Piper for speech synthesis. Perfect for those who want complete privacy and local control. Watch Episode 3
What’s Next?
I’m committed to creating more content based on community feedback. If you have specific aspects of Home Assistant Voice you’d like to learn more about, please:
Since October 2019, Thorsten-Voice has been supporting the open-source voice technology community. As a birthday gift to our amazing community, I’m releasing all voice datasets (neutral, emotional, and Hessisch) in their original 44kHz sample rate quality – a significant upgrade from the previous 22kHz versions.
🎯 What’s New:
• All recordings now available in pristine 44kHz quality
• Complete collection unified in one place on Hugging Face
• Includes all variants: neutral, emotional, and Hessisch dialects
• Fully structured and transcribed
This consolidated release makes it easier than ever to access and work with the complete Thorsten-Voice collection. As always, everything remains under CC0 license, continuing our commitment to unrestricted open-source voice technology.
Ich bin dankbar dafür, ein Teil des Deutschlandfunk / Deutschlandradio Podcasts „KI Verstehen“ vom 12.09.2024 gewesen sein zu dürfen 😍.
Die Moderator:innen Friederike Walch-Nasseri und Moritz Metz haben sich im Podcast-Beitrag „Open-Source-Modelle demokratisieren Künstliche Intelligenz“ mit der Wichtigkeit von Open-Source im KI-Umfeld beschäftigt. Ein ganz wichtiges Thema, um Vertrauen in die Schlüsseltechnologie KI aufzubauen und beizubehalten.
Ich (Thorsten Müller) durfte nicht nur persönlich mitreden, sondern auch meine künstliche Stimme „Thorsten-Voice“ durfte einige ihrer sprachlichen Fähigkeiten (ach uff Hessisch) unter Beweis stellen 😊.
Hört gerne in diese und auch die anderen absolut hörenswerten Folgen rein und abonniert den Podcast „KI Verstehen“. Ihr findet ihn überall, wo es Podcasts gibt, oder direkt auf der Deutschlandfunk-Website.
Einfach aus privatem Spaß (nicht abgestimmt) habe ich, wegen meinem Lokalpatriotismus, einen Text von der Internetseite der Stadt Frankfurt genommen und mit meiner (süd) hessisch babbelnden, cloud- und kostenfreien, künstlichen „Thorsten-Voice“ TTS als Sprachausgabe „babbeln“ lassen. Und das klingt so.
In Frankfurt wohnen mehr als 750 Tausend Menschen. Frankfurt liegt mitten in Deutschland und ist in der ganzen Welt bekannt. Dabei ist Frankfurt nicht so groß wie Hamburg oder Berlin. Man kann in Frankfurt gut leben! Viele Menschen kennen Frankfurt, weil es hier viele Banken gibt. Die Banken machen auch Geschäfte mit Firmen und Menschen im Ausland. Viele Menschen kommen nach Frankfurt, weil hier große Messen stattfinden. Zum Beispiel die Musikmesse. Auch aus dem Ausland kommen viele Besucher und Besucherinnen zu diesen Messen. Frankfurt hat auch viele Hochhäuser. Und der Flughafen ist einer der größten in Europa. Nicht weit von den Hochhäusern finden Sie gemütliche Apfelweinkneipen und in der ganzen Stadt gibt es viele Ausflugsziele. Manche dieser Ausflugsziele sind schon sehr alt. Zum Beispiel der Kaiserdom oder die Paulskirche. Ein sehr berühmter Frankfurter war Johann Wolfgang von Goethe. Das spricht man so: Göte. Er hat vor etwa 300 Jahren hier gelebt und war ein berühmter Dichter. Dichter bedeutet: Er hat viele Geschichten geschrieben. Die sind in der ganzen Welt berühmt. Man lernt die Geschichten sogar in der Schule. Göte ist in Frankfurt geboren. Aber das ist viele hundert Jahre her. Er lebt schon lange nicht mehr. Trotzdem kennen ihn viele Menschen. Weil er so berühmt ist. Darauf ist Frankfurt besonders stolz. Sie können das Haus besichtigen in dem Johann Wolfgang von Goethe geboren wurde. Frankfurt ist eine sehr grüne Stadt. Es gibt viele Parks und den großen Stadtwald. Am Mainufer können Sie die schöne Aussicht genießen. Zum Beispiel beim spazieren gehen, beim joggen, beim Radfahren oder Picknicken. Und dort sind auch viele bekannte Museen wie zum Beispiel das Kunst-Museum Städel oder das Deutsche Film Museum. Hier finden Sie noch mehr zu den Museen in Frankfurt in Leichter Sprache. Hier haben wir auch noch ein paar Ausflugs-Tipps für Sie rund um Frankfurt im sogeannten Grün-Gürtel Was das alles ist erfahren Sie wenn Sie auf das Wort Grün-Gürtel klicken. Möchten Sie die Stadt Frankfurt besichtigen? Sie finden bestimmt viele interessante Orte und haben Spaß dabei!