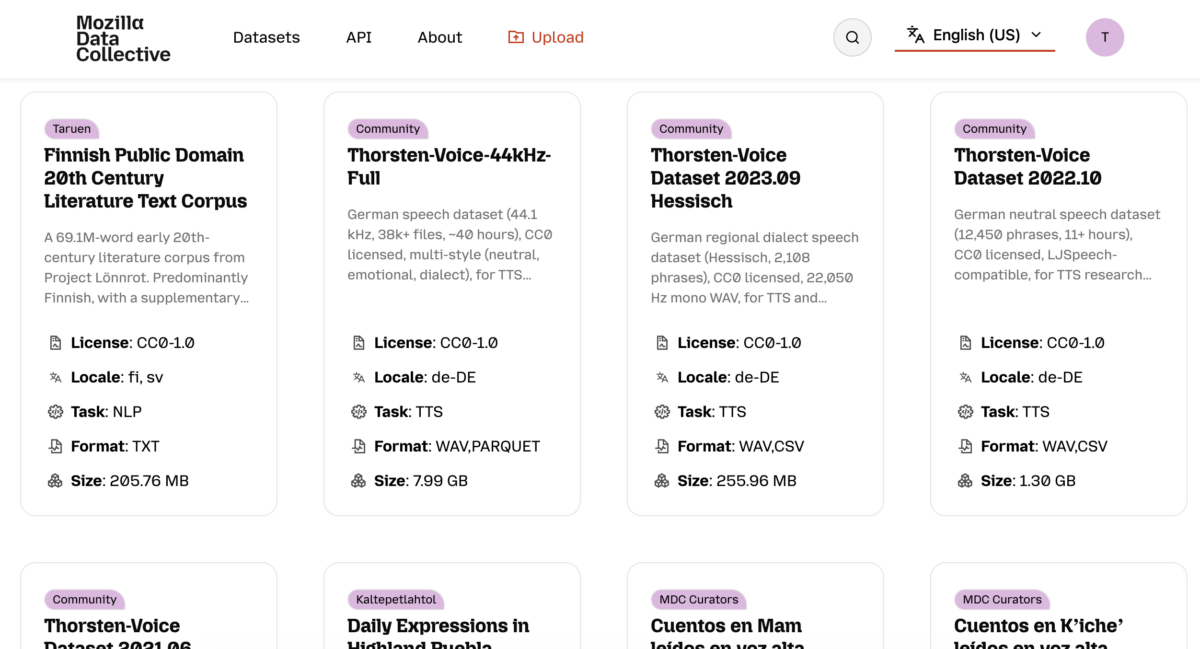
All my Thorsten-Voice speech datasets are now also available via the Mozilla Data Collective (MDC).
This includes:
- TV-2021.02-Neutral
- TV-2022.10-Neutral
- TV-2021.06-Emotional
- TV-2023.09-Hessisch
- TV-44kHz-Full (approx. 40 hours, 38,000+ recordings)
The datasets remain released under the CC0 public domain dedication and are free to use for both research and commercial applications.
Mozilla Data Collective now serves as an additional open distribution channel alongside Zenodo and Hugging Face, further increasing accessibility and long-term availability.
The goal of Thorsten-Voice remains unchanged: to provide high-quality German speech datasets as open resources for text-to-speech research, development, and innovation.
Thanks Mozilla Foundation for your nice LinkedIn post 😊.